
Overview of the integrated Saidot-Azure evaluation capability
The Saidot-Azure evaluations streamline technical evaluation workflows with automated evaluation plans and connect technical evaluations to end-to-end AI governance workflows. The evaluations are available for model deployments built in Azure AI Foundry and imported to Saidot for AI governance. The guidelines for integrating Saidot to Azure AI Foundry and using the Model Catalogue can be found here.
Saidot evaluations enable you to conduct
Regular testing to help you understand the performance and quality of your generative AI system, leveraging a range of tailored metrics such as groundedness, relevance, fluency, F1 score, ROUGE, among others.
Red teaming to help you proactively identify and measure a likelihood of safety-related risks associated with your generative AI systems for content safety, security and data confidentiality vulnerabilities.
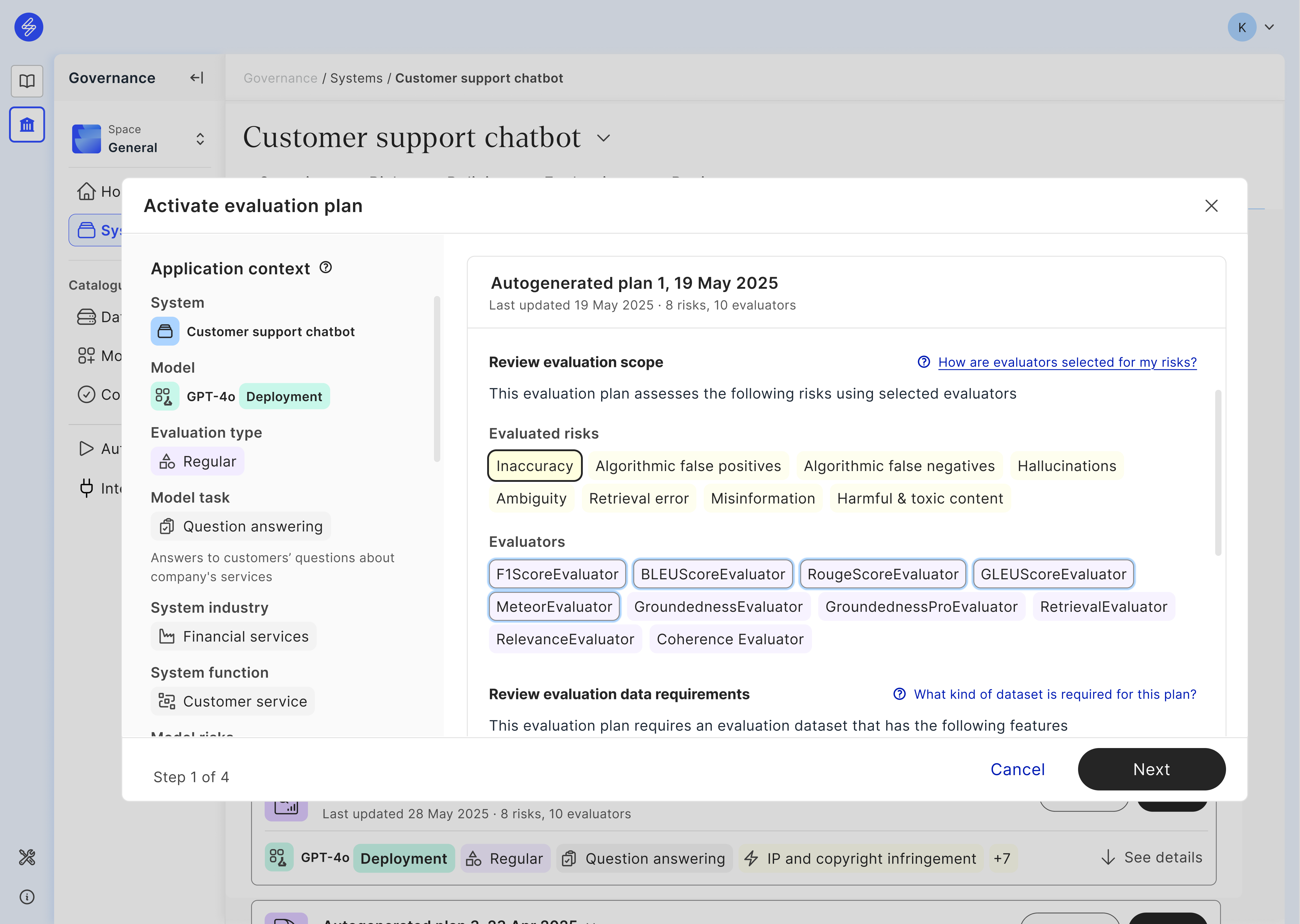
To streamline the scoping of technical evaluations, Saidot autogenerates evaluation plans for regular testing and red teaming based on the system context, deployment, tasks, risks and the evaluators matching such application context. The guidelines for specifying the system context while registering the system can be found here. The instructions for how to identify, evaluate and manage the AI system risks can be found here. To ensure the relevance of autogenerated evaluation plans, users are encouraged to review and confirm model tasks and associated model risks used for generation. From among the generated plans, users can review and select the relevant ones through an evaluation plan activation process.
By activating an evaluation plan in Saidot, users generate a tailored evaluation notebook containing everything they need to execute the evaluations in Azure and pass the results back to Saidot. After running the evaluations in Azure, the evaluation reports can be accessed and analysed further in Saidot. Based on the results, technical guardrails can be implemented in Azure when needed, and re-evaluated in Saidot. Finally, the results will be then further integrated to inform risk and compliance processes.
Getting started
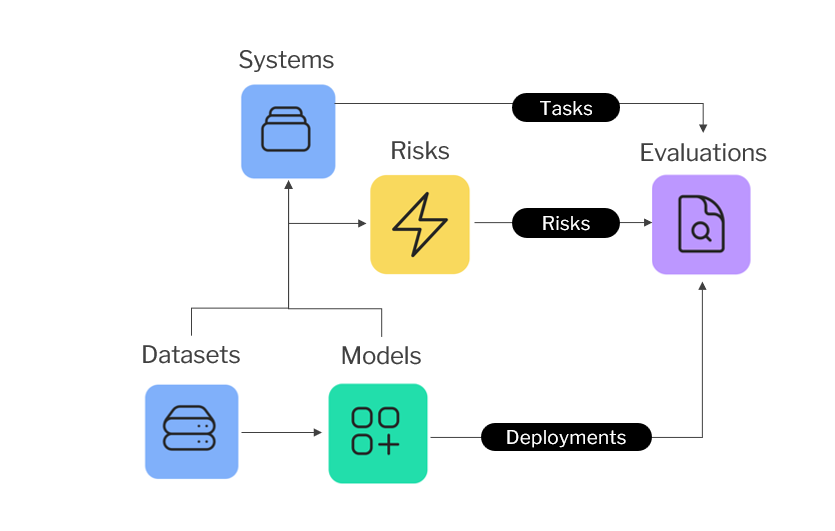
After registering the system, linking the Azure model deployment with tasks relevant to your system from the Model Catalogue, Evaluation plans will be automatically generated to your system. Whenever there are pre-identified model risks available for your linked model via the Saidot Library, risk based red teaming plans will be also automatically generated. Users can also add custom model risks directly to their system, further extending their red teaming plans with such custom risks. If the system is missing the needed contextual information, the Evaluation tab will be empty and users are instructed to linking deployments first.
Supported risks and evaluators
When creating evaluation plans, we support two main types: regular testing and red teaming. Each plan focuses on assessing different kinds of risks and uses specific evaluators to test your system.
Regular testing plans are designed for evaluating the performance and quality of your system. To generate regular evaluation plans, we start by identifying the tasks your deployment performs, and match them with suitable evaluators. To maximise the utility of each plan, we group evaluators that require the same kind of evaluation dataset and collect risks connected to those evaluators to generate a regular testing plan.
Red teaming plans help simulate potential attacks or unwanted behaviors of your system. To generate red teaming plans, we take the pre-identified risks from your model deployment or the custom risks added directly to your system, and identify any red teaming compatible evaluators linked to these risks. For such risks we identify applicable red teaming strategies and any further risks supported by each strategy. Finally we group evaluators by their data requirements to create red teaming plans.
In both types of plans, the goal is to create ready for execution evaluation plans connecting the right evaluators with the risks relevant to your system, ensuring that each part of your system is tested effectively. Users can review the evaluation scope and mappings when activating their evaluation plans before notebook generation.
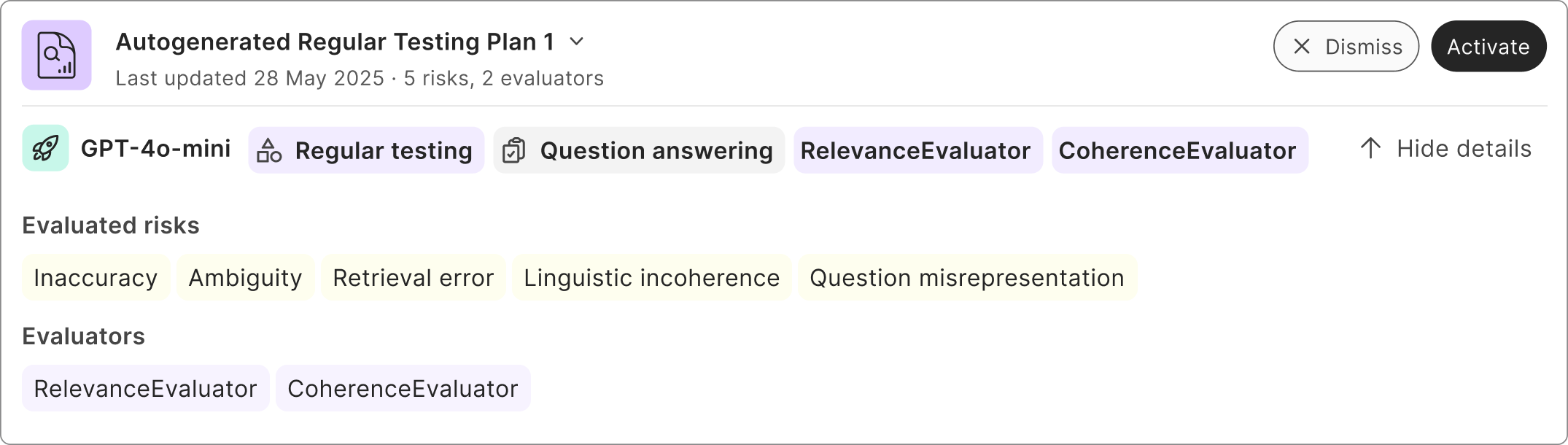

Currently, Saidot automated evaluation plans support evaluation of 44 risks with regular testing, and evaluation of 17 risks with red teaming. In the testing plan activation process, users can explore the details of each evaluation. This includes reviewing the specific tasks, risks, and evaluators involved. By hovering over any evaluated risk, you can see which evaluators are used for that particular risk.
Evaluation data
Each evaluation plan on Saidot share the similar dataset requirements. This way, the entire plan can be evaluated with one evaluation dataset. Dataset types and requirements per each evaluation plan can be reviewed in the evaluation plan activation flow.
Dataset types
Built-in evaluators can accept either query and response pairs or a list of conversations:
|
Type |
Description |
|---|---|
|
Query and response pairs |
Individual pairs consisting of a user input (query) and a model-generated or human-written response, in .jsonl format. Can also include context and ground truth. Useful for evaluating single-turn generation quality. Suitable for all evaluators. Example: |
|
List of conversations |
For evaluators that support conversations for text, you can provide Example: The Microsoft evaluators understand that the first turn of the conversation provides valid |
Dataset requirements
The dataset requirements will always be shown for you in the evaluation plan. If dataset simulation is selected, the dataset will be generated in the appropriate format. For more information, please see: https://learn.microsoft.com/en-us/azure/ai-foundry/how-to/develop/evaluate-sdk#data-requirements-for-built-in-evaluators.
|
Requirement |
Description |
|---|---|
|
Query → |
The user input or prompt that initiates the model's response. Should reflect realistic and diverse scenarios relevant to the deployment context. |
|
Response → |
The output generated by the system in response to the query. |
|
Context → |
Information that may influence the response, such as information about the system tasks and intended use case. Important for evaluating context-aware behavior. |
|
Ground Truth → |
The expected or ideal response, typically verified by human experts. Used as a reference for accuracy and alignment evaluation. |
Dataset options for evaluation plans
After reviewing the evaluation scope and dataset requirements, users can select their preferred dataset approach. We provide different dataset appraoches depending on your evaluation plan and feasible options.
For regular testing, users can select an option of generating simulated dataset that is grounded to their own dataset using Azure AI Search and generation SDK, or an option to upload their own evaluation dataset. For red teaming, we offer an option to simulate an adversarial dataset with Azure enablers. The code for creating datasets using the user selected approach is provided as part of the evaluation Notebook created at the end of the evaluation plan activation process. Simulated data is generated in Azure using Azure enablers during the Notebook's execution. Saidot evaluation plan dataset size defaults to N=30 for regular testing plans and N=30 per attack type for red teaming plans.
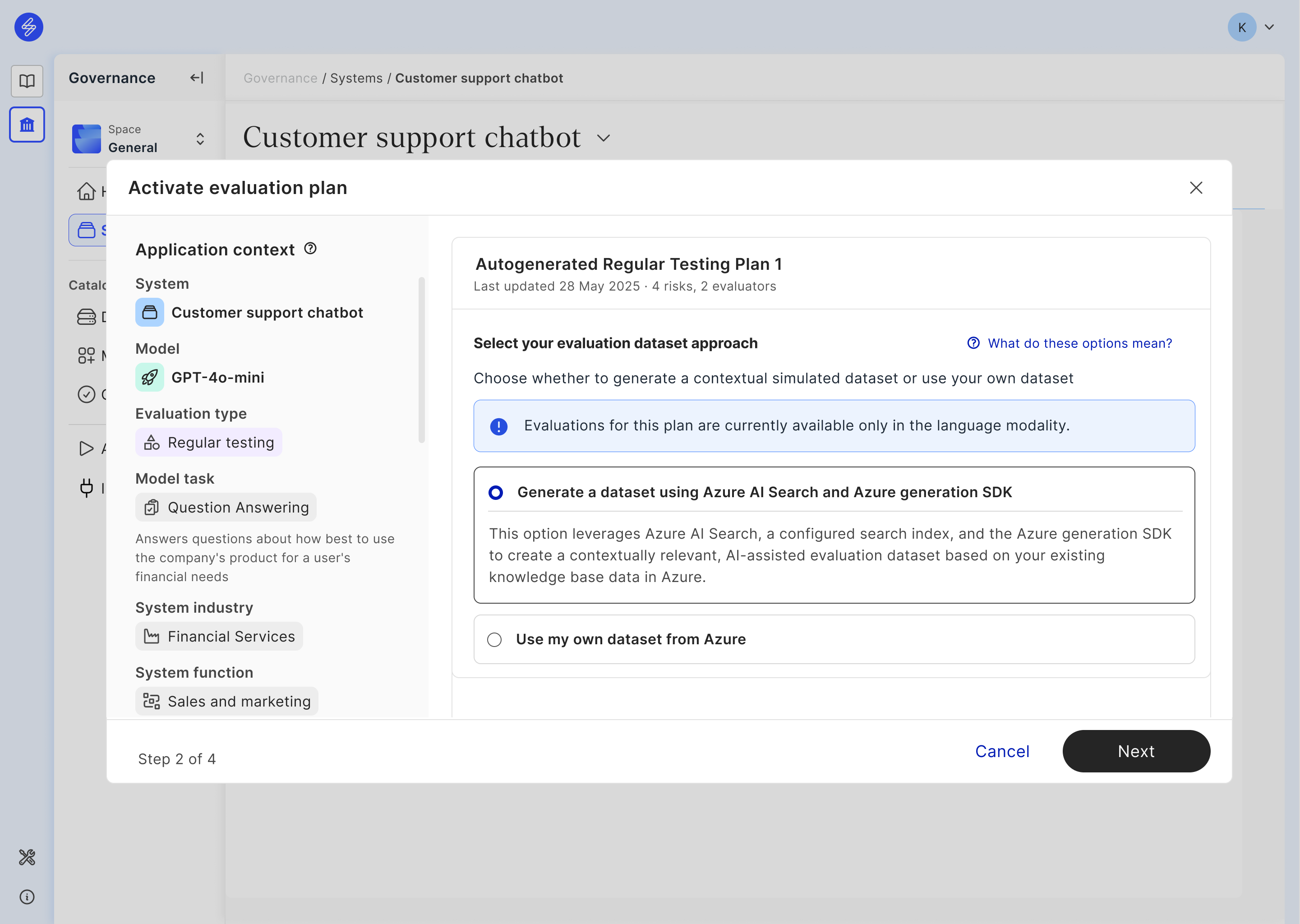
Dataset generation using Azure AI Search and Azure generation SDK
Saidot provides an integration with Azure AI Search and Azure generation SDK to support the creation of contextually relevant, AI-assisted evaluation datasets. These datasets are generated using your existing knowledge base data within Azure, aiming to support context-aware model evaluations. With the help of Azure AI Search and Azure generation SDK, users can produce datasets consisting of simulated data that will be used to conduct the evaluations listed in the activated evaluation plans on Saidot.
Generate an adversarial simulated dataset with Azure generation SDK
For red teaming evaluation plans, users can make use of Microsoft provided AI assisted evaluation dataset simulators. These AI-assisted capabilities are fully provided and operated by Microsoft. Users can review and manage the simulated data generation setup directly within Azure. Saidot’s role in the simulated data generation process is limited to providing a structured evaluation plan and Notebook that guides the simulated data generation logic at Azure. Please refer to Microsoft documentation for further details on simulated data generation on Microsoft Learn: https://learn.microsoft.com/en-us/azure/ai-foundry/how-to/develop/simulator-interaction-data#generate-text-or-index-based-synthetic-data-as-input
Use your own dataset from Azure
For regular testing plans, users can also choose to upload or reference a custom dataset stored in their Azure environment. This option gives users a full control over the evaluation data. If using this option, users must ensure that the dataset meets the specific requirements defined by the selected evaluation plan. Only datasets that align with these requirements can be used during the evaluation process.
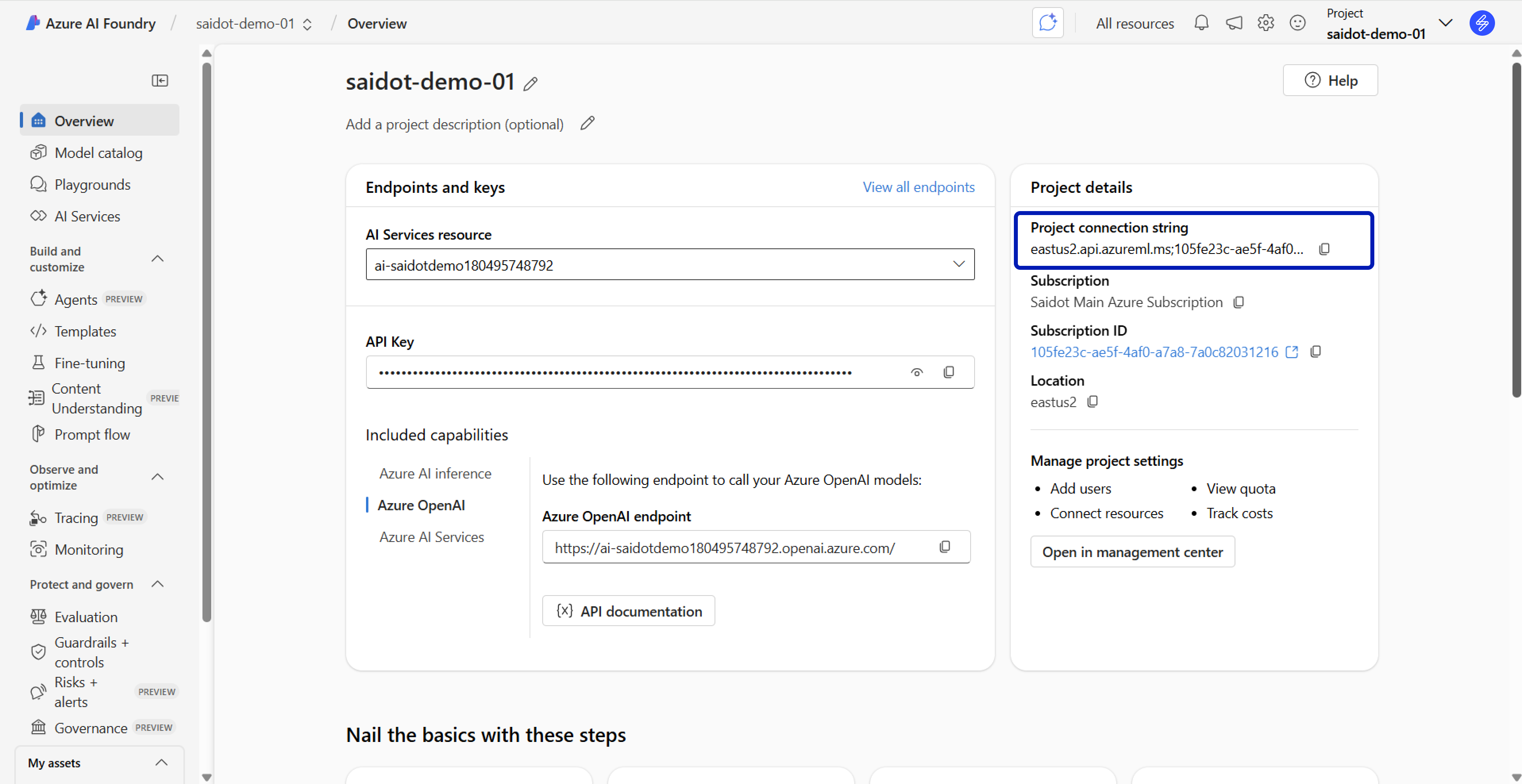
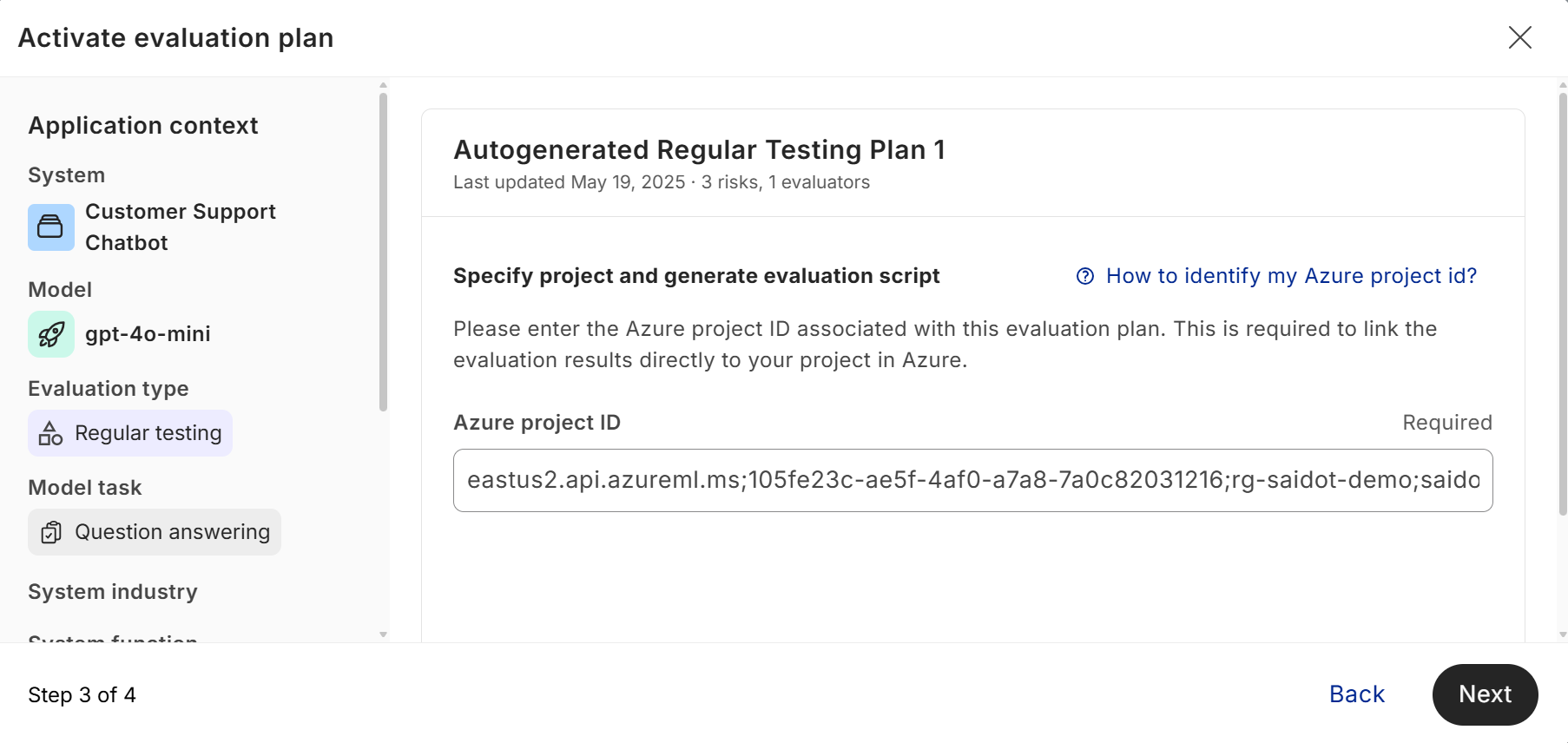
Connecting evaluation plans to Azure project
In order to connect the evaluation results to your respective project in Azure, you will need to specify the project prior to generating the evaluation script. This project will be automatically prepopulated to your evaluation notebook in the code generation.
Executing evaluation plans in Azure
Saidot generates one notebook per each activated evaluation plan. Evaluation notebooks vary depending on whether a regular testing or a red teaming plan is activated. The notebook generated in Saidot is a step-by-step guide that shows how to evaluate an AI model’s behavior using tools provided by Azure AI capabilities. The evaluation script notebook that is autogenerated in Saidot can be downloaded and then executed in Azure. Guidelines for executing evaluation notebooks using with Visual Studio can be found from this page: https://visualstudio.microsoft.com/
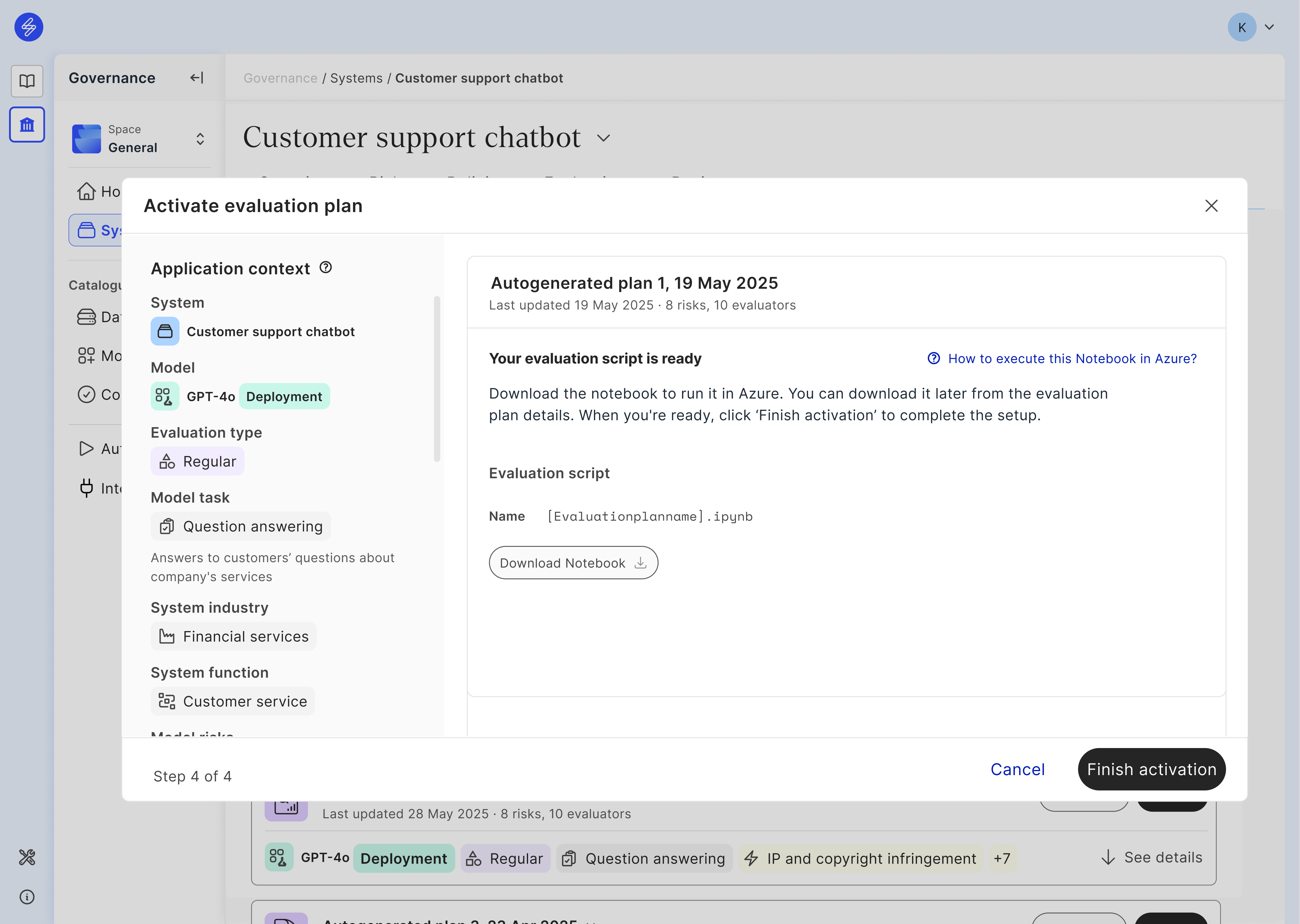
Regular Evaluation Plan Notebook
This notebook is used for general-purpose AI system evaluations, such as relevance or coherence. The generated notebook has the following structure:
1. Installation
Installs required Python packages from Azure AI SDKs:
%pip install azure-ai-evaluation
%pip install azure-identity
%pip install azure-ai-ml
%pip install azure-ai-projects
2. Imports
Imports necessary Python packages (tools) that will be used to connect to the Azure AI environment, load models and test data and run evaluations.
3. Azure Project Connection
Sets up access to the Azure AI Foundry project using prepopulated environment variables based on your Saidot - Azure integration details, and project string provided in the evaluation plan activation. This connection ensures that your evaluation results are linked to the right Azure AI Foundry workspace.
4. Azure Model Deployment Connection
Configures the model deployment that will be used to evaluate and the deployment being evaluated, and how to access them. We will prepopulate this connection with the respective deployment defined by your evaluation plan.
5. Dataset Setup
Provides a code for dataset simulation using Azure AI assisted simulators, or referencing your existing evaluation dataset as defined in the evaluation plan activation flow.
6. Prepare Data for Evaluation
Sets up the Azure client and uploads a dataset that will be used for the evaluation plan (either regular or red teaming).
7. Evaluation Execution
Runs the evaluation using Azure’s evaluators as defined in evaluation plan, and collects results for reporting.
Evaluation reports on Saidot
After running the report in Azure, the report will be automatically added to the respective evaluation plan on Saidot. When accessing evaluations from the Evaluations tab, you can use sort option ‘Reports’ to quickly access evaluation plans with reports available. Each evaluation notebook run in Azure will create its own report on Saidot, allowing the comparison of the results after implementation of the technical guardrails or other changes in the model deployment.
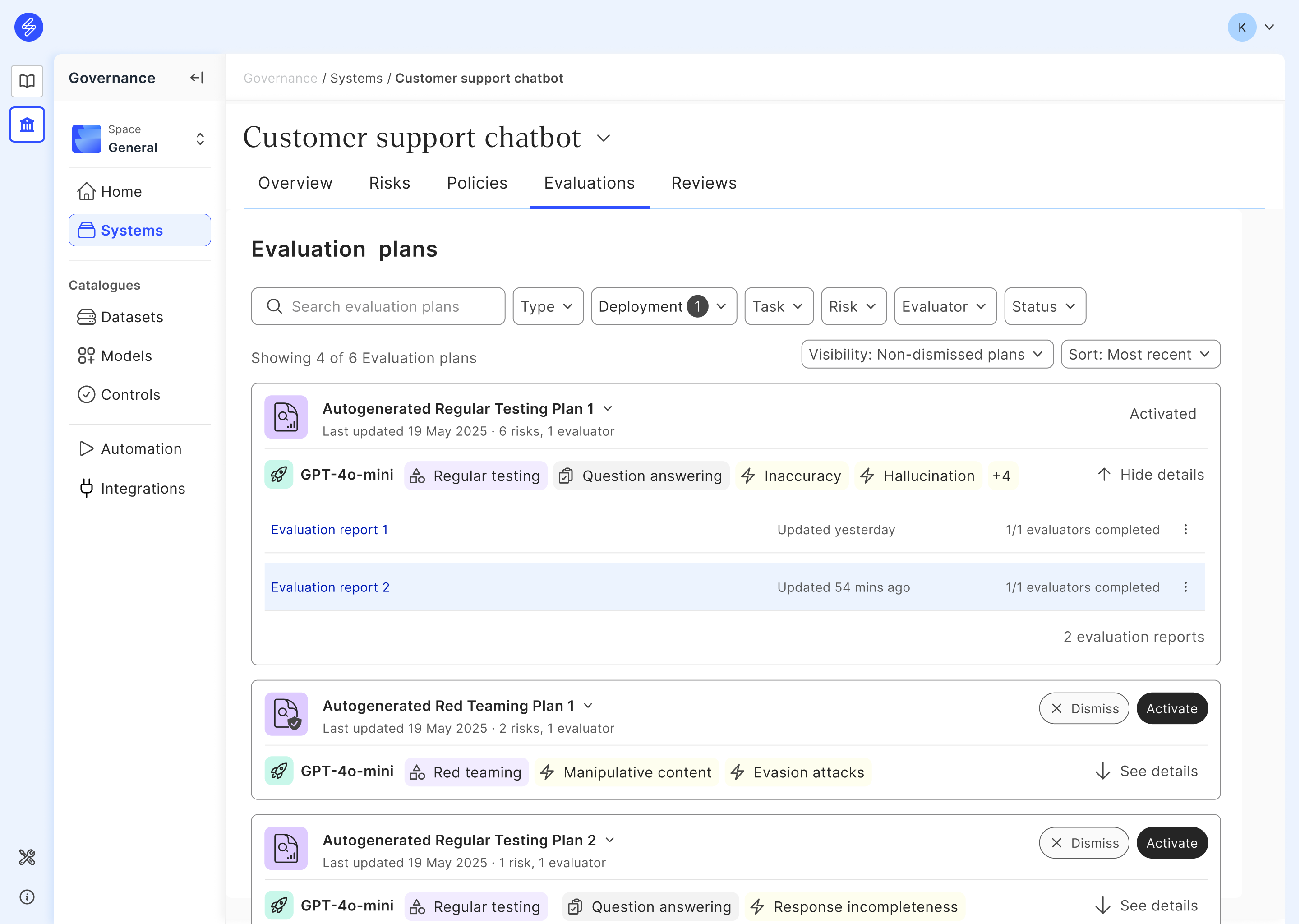
Evaluation reports on Saidot contain evaluation metrics cards, application context, and evaluation deport details.
Metrics cards provide test case distribution to categorised scale presented as histograms, and an aggregated value across all test cases. Each metric card has an explainer for quick explainer of each metric and the metric scales. Metrics cards can be sorted and filtered using various filters, and searched based on metric name. If there are more than one report available for the gven evaluation plan, users can also access 'Compare to' filter providing side-by-side comparison of the two evaluation runs and reports.
To help users interpret the evaluation report, users can access the application context and evaluation report details via the left panel. Application context provides information of the context used for evaluation plan generation, and evaluation dataset generation, including system name, deployment name, evaluation type, system industry, system function, and model task and linked model risks. Evaluation report details provides the detailed information about the specific configurations during the run, including run id, run time, evaluators, evaluation dataset, and active technical controls. Using this panel users can also provide a more descriptive name to their evaluation report using rename functionality, or delete the given evaluation report.
More information in Azure
Azure documentation: Evaluation of generative AI applications
Azure documentation: Evaluation and monitoring metrics for generative AI